Introduction
Introduction The Long Journey of Data Classification: How Humanity Organizes Information
Humans have an innate urge to impose order by sorting things into groups with similar features. This allows us to understand the world and make decisions more easily.
Over thousands of years, different civilizations have created increasingly complex classification systems to categorize concepts, objects and data for purposes like record-keeping, communication and governance. Advancements in science and technology have enabled people to classify at greater scales with more accuracy.
This article traces major milestones in humanity’s quest to systematically classify data, from ancient times to the modern era of powerful computers and algorithms. The winding path reflects intellectual progress in our never-ending battle to tame information overload.
Key Takeaway: Classification provides tools to wrangle messy reality into orderly frameworks aiding comprehension and choice. Each era builds new models, technologies and applications, but the core impulse remains constant – distilling chaos into clarity as knowledge grows.
From Clay Tokens to Cloud Computing: Classifying to Understand, Decide and Administer
Ancient Record-Keeping Needs Drive Early Data Organization
The earliest classifications assisted administration for growing societies’ governance, infrastructure and trade:
- Ancient Egypt held periodic censuses to count subjects, monitor the population and pool labor for major projects like pyramids. Categorizations assisted taxation too.
- Ancient China gathered agricultural data like harvest dates, transport logs and granary volumes to aid regional planning. Livestock and grain were classified and tallied.
- Ancient Rome carved census figures into stone tablets. Numbers categorized citizens’ gender, ages and locations to inform taxation, conscription rates and voting rolls.
Resource planning and tribute extraction necessitated measurement. But the desire to classify nature also helped ancients make sense of the world’s bewildering diversity.
Early Classification Aids Comprehension Alongside Control
Beyond administrative utility, classification supported investigatory science and commerce:
- Ancient Greek philosophers classified observed phenomena conceptually into elemental categories like water, fire, earth, air and aether.
- Ancient Indian Ayurveda practitioners grouped medicinal plant and animal extracts by heating/cooling qualities and effects on bodily health.
- Medieval Islamic scholars categorized entries in pharmacopeias and encyclopedic texts for reference. This organized knowledge inheritance.
- Renaissance botanists classified plants based on structures like flowers, fruits and seeds. They studied interrelationships and cultivated exotic species.
- Enlightenment chemists classified elements like oxygen and lead into the periodic table according to atomic weight and reactive properties.
Classification provided cognitive grip on reality’s bewildering diversity across disciplines. Conservatively organizing knowledge aided learning too, even amid shifting paradigms.
Modern Classification Matures into Rigorous Information Science
Innovations from 1500-1950 AD expanded and strengthened classification’s scope, scale and scientific foundations across academia, government and business.
Linnaean Taxonomy Standardizes Naming and Studying Lifeforms
Carl Linnaeus’ 18th century taxonomy introduced consistent categories and Latinized scientific names for organizing Earth’s organisms. His nested hierarchy of kingdom, phylum, class, order, family, genus and species balanced specificity alongside generalization.
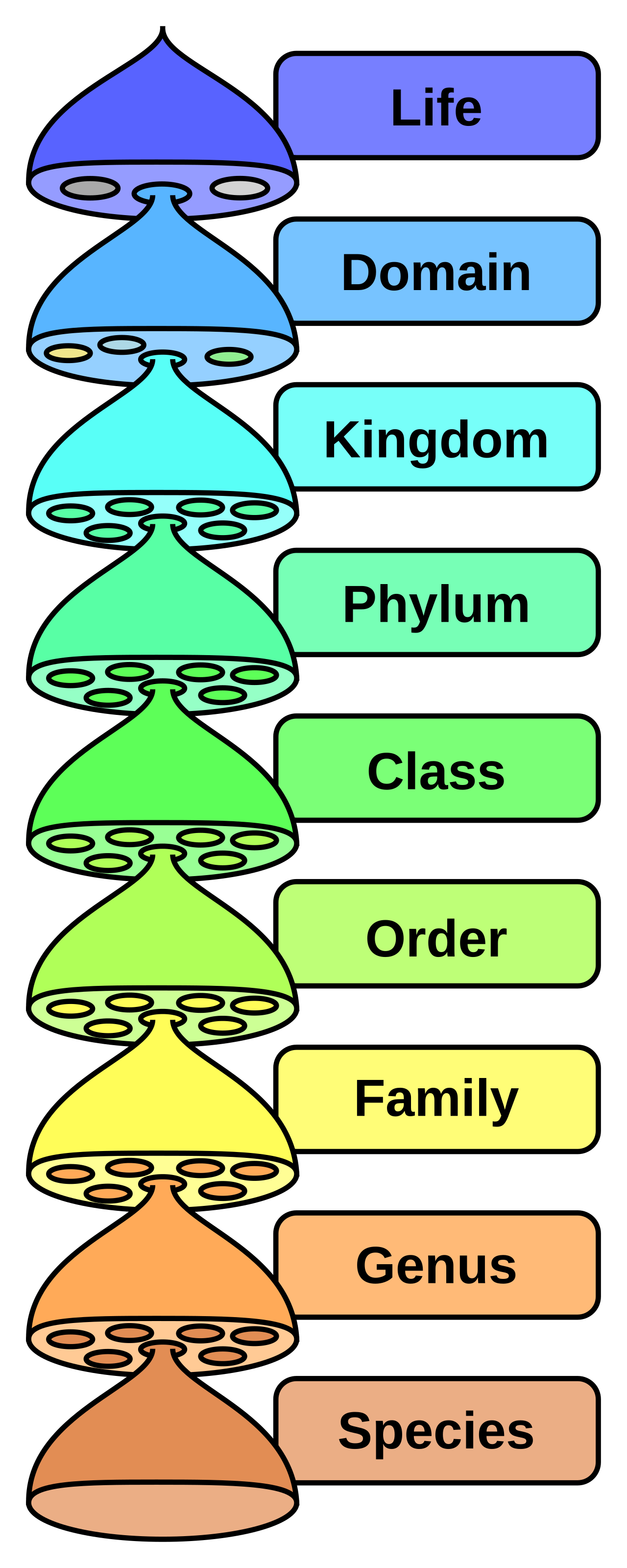
This standardized framework fueled discoveries by stabilizing disciplinary communication. It remains central to modern zoology, microbiology and botany.
Data Visualization and Statistics Enable New Insights
Data visualization and statistical analysis techniques empowered fresh ways to classify and interpret information:
- Joseph Priestley visualized timeline charts for biographical and historical data.
- William Playfair pioneered modern line, bar and pie graphs displaying numeric trends.
- Florence Nightingale depicted hospital mortality causes via polar area “coxcomb” graphs.
Probability theory and distributions for regression analysis also emerged. Adolphe Quetelet pioneered applying statistical classification to social data. More rigorous mathematical classification fueled decision-making.
Organizational Systems Tame Knowledge Databases
Standardizing classification frameworks was vital for managing institutional information flows:
- Melvil Dewey’s decimal system revolutionized libraries’ organizational capacity.
- Eugenius Warming classified ecological biomes, improving environmental science communication.
- The periodic table lent chemistry a unifying structure relating elements’ properties.
Common languages powered collaboration on accumulating knowledge.
Tabulating Machines Enable Large-Scale Classification
Specialized hardware and process tools boosted speed, scope and detail for structured categorization tasks:
- Punched card machines helped tabulate massive datasets for business billing, inventory, payroll etc.
- Typewriters and index card cataloging aided clerks.
- Government surveys and academic studies expanded via classification.
With computational help, organizations classified at unprecedented scales.
Classification Permeates Modern Science, Governance and Commerce
Classification became integral to 20th century business operations, policymaking, research and mass media. Pervasive tech amplifies this.
Corporate Data Mining Drives Marketing and Efficiency
Detailed consumer classifications now underpin corporate strategy and operations:
- Demographic data like age, geography and income brackets help segment target markets.
- Credit rating formulas classify individuals’ financial risk profiles utilizing 1000s of inputs.
- Customer relationship management (CRM) platforms classify interactions to optimize sales funnels.
- Enterprise resource planning (ERP) software integrates internal classifications across departments like accounting, manufacturing, HR and more.
Granular classification analytics guide billions in spending.
Classification Shapes Academic Research and Public Policy
From psychology to political science, classifications powerfully shape understanding:
- Personality tests like Myers-Briggs classify personalities into types using question batteries. These underlie recommendations in education, career matching and clinical fields.
- Psychiatric diagnosis classification manuals standardize disorders and conditions, defining treatment protocols. Updates periodically spark contention.
- Census racial/ethnic classifications carry massive influence on legislation, affirmative action, districting and fund allocation. Lines and labels mold society regardless of scientific validity.
Quantitative abstractions imprint significances with material consequences, despite methodological debates. Conflicts continue between cases fitting neatly into constructed categories versus framework limitations. Misclassification breeds real injustice. Disciplined, ethical practice is thus vital when policies hinge on classification rigor.

Classification Algorithms Permeate Digital Infrastructures
Classification now happens automatically at massive scope thanks to algorithms, APIs and silicon computing hardware:
| Industry | Classification Use Cases |
|---|---|
| Advertising | Classifying user traffic to target segments |
| Banking | Detecting fraudulent transactions |
| Communications | Categorizing customer ticket issues |
| Education | Grading exam responses |
| Entertainment | Recommending relevant films and music |
| Governance | Flagging dangerous emails or texts |
| Healthcare | Diagnosing conditions; predicting patient risks |
| Insurance | Assessing policy qualifications and risk factors |
| Judiciary | Predicting flight or recidivism risk |
| Manufacturing | Monitoring equipment sensor streams ; optimizing inventories |
| Publishing | Organizing document similarities for retrieval |
| Retail | Dynamically grouping products; forecasting demand |
| Search | Determining relevant results for queries |
| Social media | Ranking content by interest categories |
| Transport | Categorizing traffic patterns; classifying vehicle damage |
Custom classification engines enhance user experiences, increase efficiency and aid predictions. But biases can perpetuate too if the human contexts and constraints behind data get ignored. Thoughtful auditing helps catch issues early.
Cutting Edge Data Classification: Algorithms, Machine Learning and AI
Powerful advanced computing now extracts insights even from highly messy, unstructured data. New techniques also allow more contextual and continuous classification capabilities.
Algorithms Find Hidden Patterns in Expanding Data Universe
Immense global data generation strains limited human analysis bandwidth. Luckily sophisticated algorithms help surface non-intuitive trends.
Machine learning (ML) and artificial intelligence (AI) now automatically classify at massive scales using statistical and biologically inspired approaches – neural networks, decision trees, semantic clustering, reinforcement learning etc. Cloud computing provides processing infrastructure to crunch voluminous training data key for accuracy. Hardware innovations like graphical processing units (GPUs) and tensor processing units (TPUs) additionally boost capability. Capabilities leap forward yearly.
| Algorithm Type | Capabilities | Examples |
|---|---|---|
| Supervised Learning | Systems classify data using tagged human-curated training sets | Image recognition; language translation |
| Unsupervised Learning | Systems find self-organizing structure within untagged datasets | Customer profile clustering; social network community detection |
| Reinforcement Learning | Systems learn classification strategies via trial-and-error to optimize outcomes from complex environments |
Classifiers Become Embedded and Ubiquitous
Beyond improving analysis tools, paradigm shifts emerge in classification function and form factors:
- Embedded classification – Models may transition from offline reporting to live integration inside system flows for continuous intelligence and “-as-a-service” capabilities.
- Ambient classification – Networked sensors and IoT ecosystems allow persistent classification capabilities across infrastructure like appliances, vehicles, environments and wearables.
- Autonomous classification – AI agents, robots and assistants may handle new classification challenges independently in complex, ambiguous information environments based on context.
Classifiers look primed to permeate digital and physical worlds more wholly, not just processing data but aiding workflows.
Specialized and Augmented Data Classification
Alongside pervasive classification come growing varieties of tailored and human-machine classified hybrids:
- Ensemble models – Multiple classifiers like random forests strategically combine to overcome individual weaknesses.
- Expert systems and relevance feedback – Domain specialists train AI to recognize meaningful classification boundary challenges and nuances in specialized disciplines.
- Generative learning techniques like reinforcement learning where agents freely attempt then refine classification strategies based on environmental feedback.
- Biologically-inspired algorithms copying brain structure evolution for sensory processing efficiency.
No one-size-fits-all. Diverse data and use cases inspire specialized classification breeds while human guidance counters scenarios exceeding full automation. The future likely holds an explosion of classifier diversity and human-AI symbiosis.
Lingering Challenges for Data Classification
Despite epic progress, room remains for improving classification science and ethics:
Cons
- Bias and unfairness perpetuation from faulty, limited or outdated categorization frameworks
- Stereotyping, profiling and “overfitting” data models to individuals instead of understanding uniqueness
- Inflexibility and inability of models to handle new classes appearing spontaneously
- Runaway chains of misclassification propagating downstream without review
- Ethical conflicts posing harm like privacy violations or manipulative targeting
Pros
- Grounding decisions in evidence vs intuition to counter known cognitive biases
- Exposing historical discrimination by auditing and revising classification systems
- Automating consistency for repetitive decisions like loan qualification
- Catching high stakes cases like cancer sooner by recognizing rare subgroups
- Optimizing complex processes through pattern discovery at large scales
- Flagging model shortcomings early to guide knowledge updates
Like any tool, appropriate use and oversight matter. Classification aids comprehension but no model equals complete truth. Integrating social awareness and quantitative diligence encourages progress.
The Long Arc of Data Classification: Winding Threads into the Future
What major threads might classification weave through coming decades? Several potent trends stand out:
- A spectrum spanning automated routines to specialized human judgments – Simple classifications embed in workflows for efficiency while complex edge cases draw on human expertise. Handoffs between AI and people for hybrid decisions.
- Purpose-built classification fusion – Models integrate multiple data signals like computer vision, voice patterns and genomes for rounded judgments befitting challenges.
- Classification community science – Crowds help label diverse training data. Standards prevent fragmentation. Scientists thoughtfully probe model societal impacts.
- Co-evolution of classifiers and environments – Beyond static analysis, deployed models dynamically update environmental variables from which they learn.
- Classification for comprehension – Before generalization, foundational literacy. Education stresses critical thinking over rote categories. People interpret model outputs wisely.
The past foretells more exciting innovation as classification continues permeating science and industry. But wisdom suggests we balance automated convenience with human virtues where classifications risk oversimplifying. Joint progress uplifts more voices when priorities stay grounded in human dignity alongside efficiency.
Conclusion Data Classification
Across thousands of years, classification provided frameworks making sense of reality and informing decisions – from ancient librarianship to modern machine intelligence. Each generation builds new models, tools and applications. But the core impulse remains constant, etched into the human condition – wrestling chaos into clarity as understanding deepens.
Classifications will likely grow more ubiquitous, personalized, fluid and automated going forward. Yet interactions between people and models seem destined to persist, not vanish. Scientific laws hold eternally but living knowledge stays unfinished, demanding ongoing growth and reconciliation. As classification capably shapes environments, may our choices in turn shape classification towards justice.
This wraps our journey along the winding path of classification systems through history! Let me know if any sections could use expansion or additional examples. I’m happy to add details wherever helpful to illustrate this fascinating knowledge domain.
Emprendedor en el sector de los videojuegos, tecnologica y educación. + de 20 años en videojuegos. CEO de Hydra Interactive. Fundador de Devsfromspains.

![Buildbox Free - How To Make 2D Platformer Game [PART 1]](https://e928cfdc7rs.exactdn.com/info/uploads/sites/3/2020/01/Buildbox-Free-How-To-Make-2D-Platformer-Game-PART-150x150.jpg?strip=all)

